Text mining/text analytics is the process of deriving meaningful information from natural language text. It usually involves the process of structuring the input text, identifying patterns within the structured data and evaluating and interpreting the outcome. Natural language processing (NLP) refers to the artificial intelligence method of communicating with an intelligent system using natural language. Text mining refers to the process of deriving high-quality information from the text. The overall goal here is to turn the text into data analysis via the application of NLP.
There is scope for clinical text mining in the following scenarios:
- Summarising lengthy blocks of narrative text such as clinical notes or academic journal articles.
- Mapping data elements present in unstructured text to structured fields in an electronic health record, including the automatic assignment of ICD-9 codes to patient records and extracting textual information from the digital medical record.
- Answering unique free-form questions that require reference of multiple sources.
- Core applications are representation learning, information extraction and clinical predictions.
- The concept of medical language processing in the form of several systems developed for parsing medical language for the purpose of assisting healthcare personnel.
- Friedman and Hripcsak (1999) present the current (in 1999) NLP systems for medical texts such as the Linguistic String Project system (LSP), used in discharge letters, progress notes and radiology reports, and the Medical Language Extraction and Encoding system (MedLEE), used to extract, structure and encode clinical information.
- MENELAS is an access system for medical records using natural language to extract information from discharge summaries in French, English and Dutch. An NLP system developed at Geneva Hospital can process French, English and German.
- Continuous voice recognition will assist the physician in entering text to the patient record; simultaneously, the patient record will be encoded in the standard codes using standard terminology.
- In a study by Velupillai and Kvist (2012), the authors present three scenarios of adverse event surveillance, decision support alerts and automatic summaries where clinical text mining is used.
Natural language processing (NLP) is the traditional term for intelligent text processing where a computer program tries to interpret what is written in natural language text or speech using computational linguistic methods. Other common terms for NLP are computational linguistics, language engineering or language technology.
NLP is divided into two major components: natural language understanding and natural language generation. Natural language understanding is mapping the given input into natural languages and converting it into useful representations of analysing those languages, whereas natural language generation is the process of producing meaningful phrases and sentences in the form of natural language from an internal library. There are five components of text analysis.
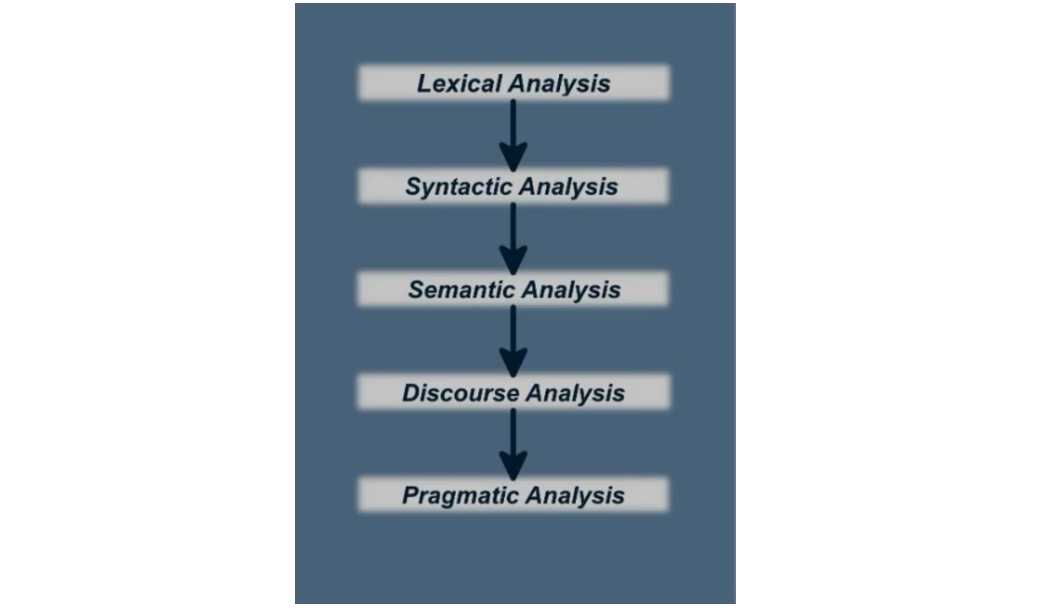
- Lexical analysis is the process of converting a sequence of characters (such as in a computer program or web page) into a sequence of tokens (strings with an assigned and thus identified meaning).
- Syntactic analysis is the process of analysing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar.
- Semantic analysis is the process of relating syntactic structures, from the levels of phrases, clauses, sentences and paragraphs to the level of the writing, to their language-independent meanings.
- Discourse analysis is an approach to the analysis of written, vocal or sign language use, or any significant semiotic event. The objects of discourse analysis (discourse, writing, conversation, communicative events) are variously defined in terms of coherent sequences of sentences, propositions, speech, or turns at talk.
- Pragmatic analysis is part of the process of extracting information from text. Specifically, it’s the portion that focuses on taking a structure set of text and figuring out what the actual meaning was.
Information retrieval (IR) may use NLP methods, but the aim with IR is to find a specific document in a document collection, while information extraction (IE) is to find specific information in a document or in a document collection. A popular term today is text mining, which means finding previously unknown facts in a text collection or building a hypothesis that later is to be proven. Text mining is, in a broad sense, the use of machine-learning-based methods. The term text mining is also used in health informatics, mostly to mean the use of rule-based methods to process clinical or biomedical text.
Here is an example of a sentence that has been tokenised.

A tokeniser must consider whether sentence delimiters should be included. Should constructions such as “let’s” be processed in one unit or not? What about the 400mg/day? How should dosage mg/day be tokenised? How about x-tra?
Usually, built-in tokenisers will have white spaces, sentence delimiters such as commas and question marks, they will be useful markers for words and they can be used as cues for simple tokenisers. However, clinical text is very noisy and contains many non-standard expressions and non-standard abbreviations; therefore, tokenisation can be cumbersome.
Technical Information
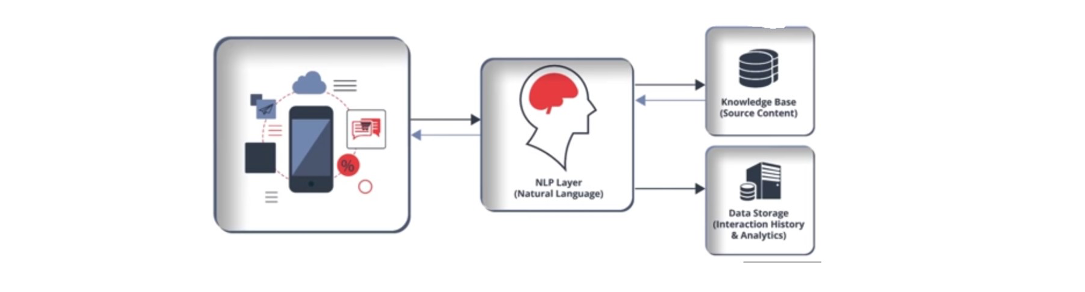
The figure below depicts the basic structure of NLP applications. In this, the NLP layer collects and exchanges information from various sources and internally connects the knowledge base and the data storage. Knowledge base is the source of all the logs from a large history of the events, which are used to train the particular algorithm. The data storage has the interaction history and the analytics of the interaction, which helps the NLP layer to generate the expected outcome.
Note: Fundamentals of NLP (tokenisation, stemming, etc.) can be found in the PHUSE Education series.
References
Basic Building Blocks for Clinical Text Processing: https://doi.org/10.1007/978-3-319-78503-5_7
Text Analytics & NLP in Healthcare: Applications & Use Cases: https://www.lexalytics.com/lexablog/text-analytics-nlp-healthcare-applications
Data integration of structured and unstructured sources for assigning clinical codes to patient stays: https://www.researchgate.net/publication/281290016_Data_integration_for_assign_clinical_codes_patient
Author
Swetha Mandava Bayer Pharmaceuticals Private Limited Madhapur, Hyderabad-500081, India. E-mail: swetha.mandava@bayer.com Web: http://www.bayer.in
